Table shards and replicas
This topic doesn’t apply to ClickHouse Cloud, where Parallel Replicas function like multiple shards in traditional shared-nothing ClickHouse clusters, and object storage replaces replicas, ensuring high availability and fault tolerance.
What are table shards in ClickHouse?
In traditional shared-nothing ClickHouse clusters, sharding is used when ① the data is too large for a single server or ② a single server is too slow for processing the data. The next figure illustrates case ①, where the uk_price_paid_simple table exceeds a single machine’s capacity:
In such a case the data can be split over multiple ClickHouse servers in the form of table shards:
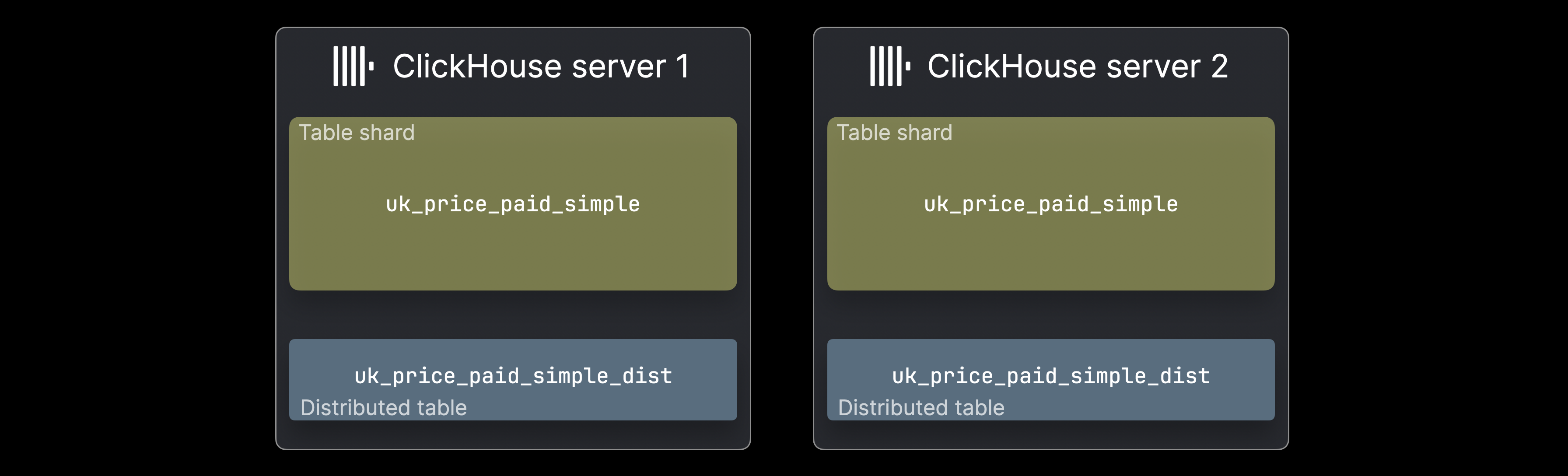
Each shard holds a subset of the data and functions as a regular ClickHouse table that can be queried independently. However, queries will only process that subset, which may be a valid use case depending on data distribution. Typically, a distributed table (often per server) provides a unified view of the full dataset. It doesn’t store data itself but forwards SELECT queries to all shards, assembles the results, and routes INSERTS to distribute data evenly.
Distributed table creation
To illustrate SELECT query forwarding and INSERT routing, we consider the What are table parts example table split across two shards on two ClickHouse servers. First, we show the DDL statement for creating a corresponding Distributed table for this setup:
The ON CLUSTER clause makes the DDL statement a distributed DDL statement, instructing ClickHouse to create the table on all servers listed in the test_cluster cluster definition. Distributed DDL requires an additional Keeper component in the cluster architecture.
For the distributed engine parameters, we specify the cluster name (test_cluster), the database name (uk) for the sharded target table, the sharded target table's name (uk_price_paid_simple), and the sharding key for INSERT routing. In this example, we use the rand function to randomly assign rows to shards. However, any expression—even complex ones—can be used as a sharding key, depending on the use case. The next section illustrates how INSERT routing works.
INSERT routing
The diagram below illustrates how INSERTs into a distributed table are processed in ClickHouse:
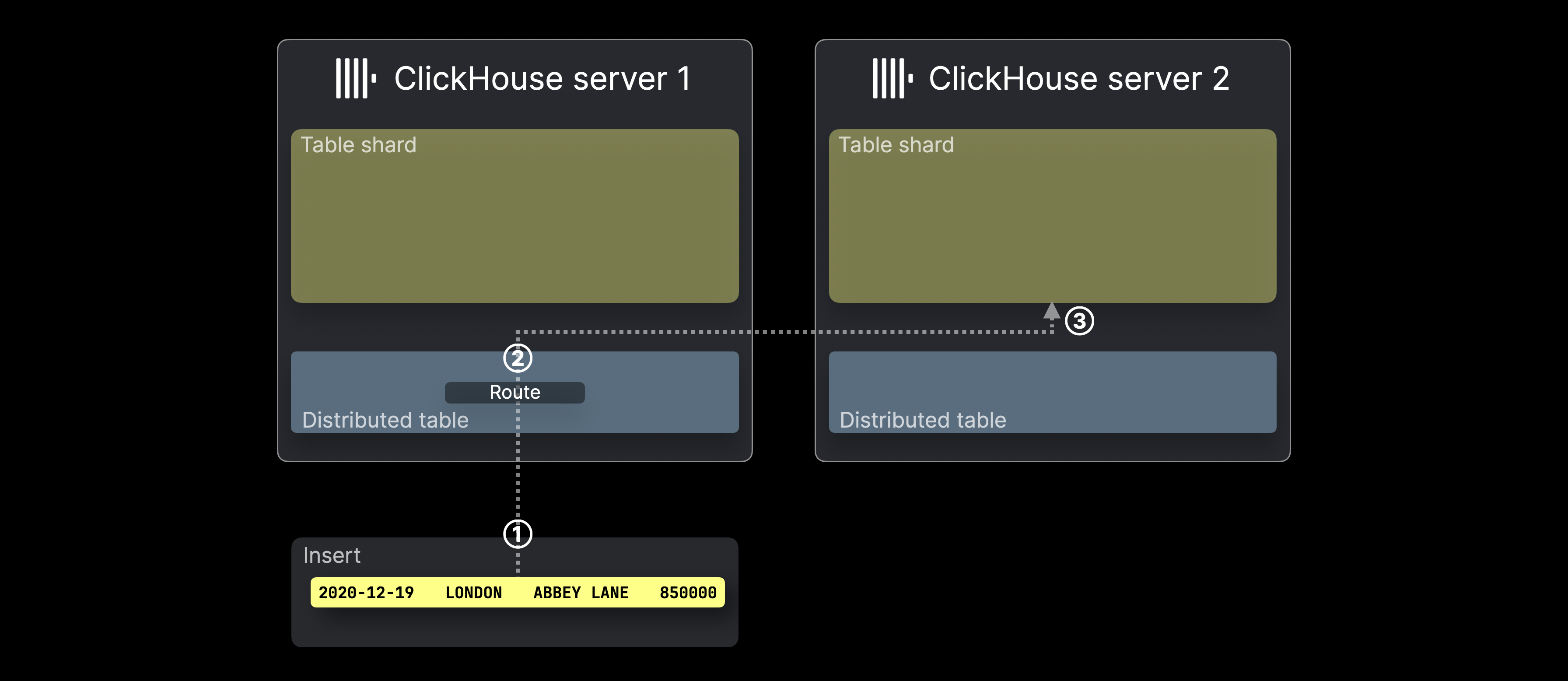
① An INSERT (with a single row) targeting the distributed table is sent to a ClickHouse server hosting the table, either directly or via a load balancer.
② For each row from the INSERT (just one in our example), ClickHouse evaluates the sharding key (here, rand()), takes the result modulo the number of shard servers, and uses that as the target server ID (IDs start from 0 and increment by 1). The row is then forwarded and ③ inserted into the corresponding server's table shard.
The next section explains how SELECT forwarding works.
SELECT forwarding
This diagram shows how SELECT queries are processed with a distributed table in ClickHouse:
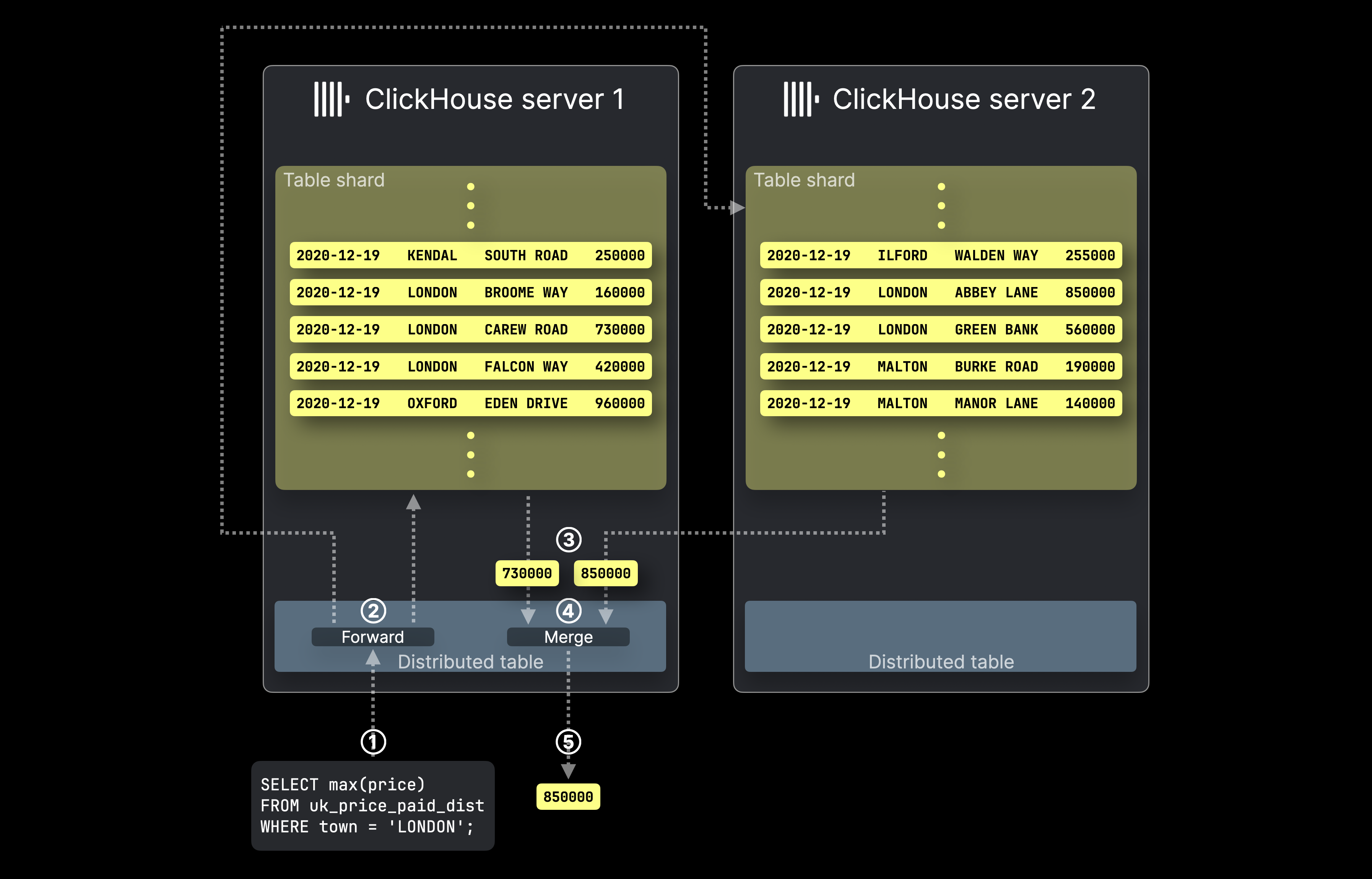
① A SELECT aggregation query targeting the distributed table is sent to corresponding ClickHouse server, either directly or via a load balancer.
② The Distributed table forwards the query to all servers hosting shards of the target table, where each ClickHouse server computes its local aggregation result in parallel.
Then, the ClickHouse server hosting the initially targeted distributed table ③ collects all local results, ④ merges them into the final global result, and ⑤ returns it to the query sender.
What are table replicas in ClickHouse?
Replication in ClickHouse ensures data integrity and failover by maintaining copies of shard data across multiple servers. Since hardware failures are inevitable, replication prevents data loss by ensuring that each shard has multiple replicas. Writes can be directed to any replica, either directly or via a distributed table, which selects a replica for the operation. Changes are automatically propagated to other replicas. In case of a failure or maintenance, data remains available on other replicas, and once a failed host recovers, it synchronizes automatically to stay up to date.
Note that replication requires a Keeper component in the cluster architecture.
The following diagram illustrates a ClickHouse cluster with six servers, where the two table shards Shard-1 and Shard-2 introduced earlier each have three replicas. A query is sent to this cluster:
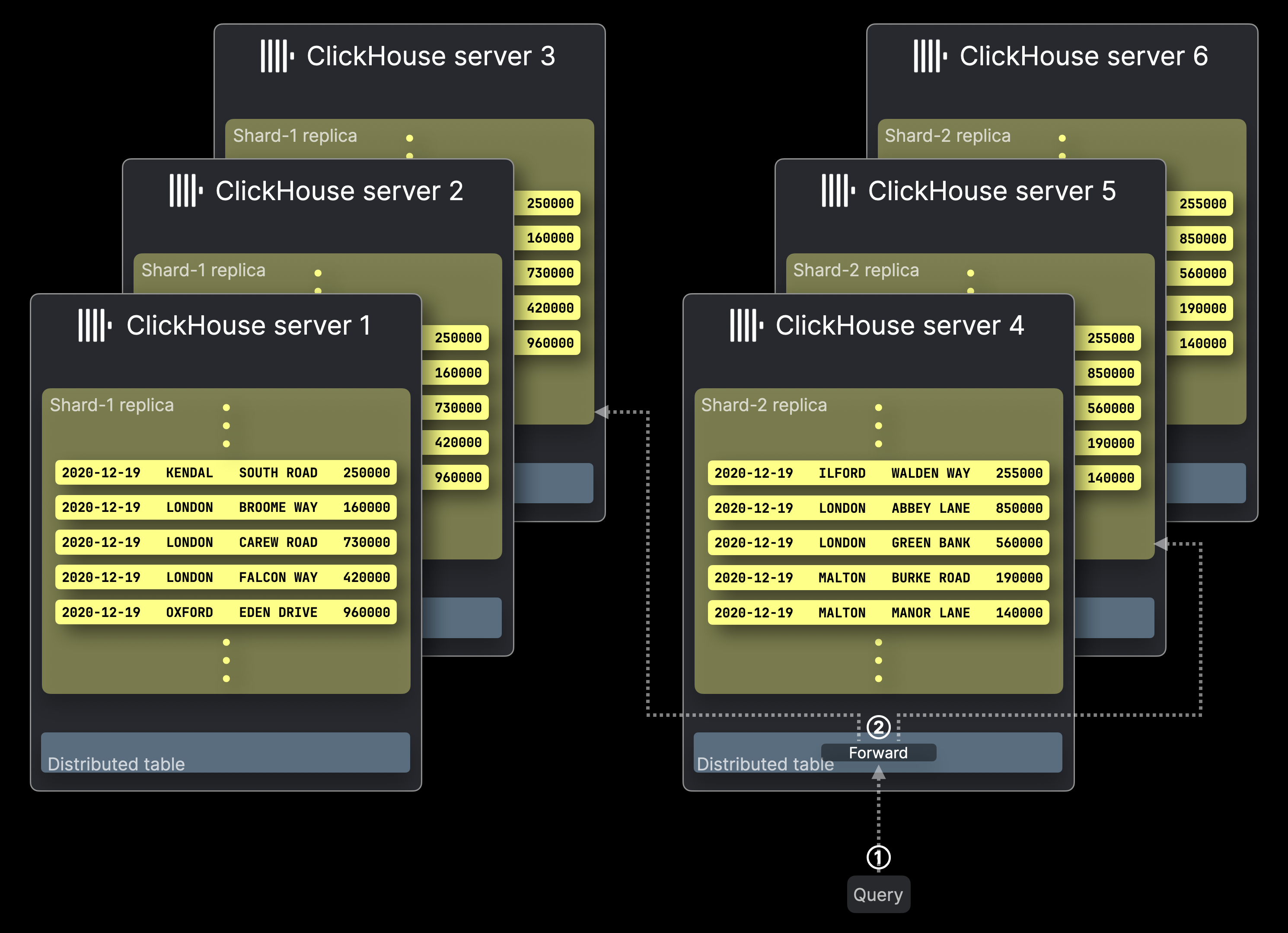
Query processing works similarly to setups without replicas, with only a single replica from each shard executing the query.
Replicas not only ensure data integrity and failover but also improve query processing throughput by allowing multiple queries to run in parallel across different replicas.
① A query targeting the distributed table is sent to corresponding ClickHouse server, either directly or via a load balancer.
② The Distributed table forwards the query to one replica from each shard, where each ClickHouse server hosting the selected replica computes its local query result in parallel.
The rest works the same as in setups without replicas and is not shown in the diagram above. The ClickHouse server hosting the initially targeted distributed table collects all local results, merges them into the final global result, and returns it to the query sender.
Note that ClickHouse allows configuring the query forwarding strategy for ②. By default—unlike in the diagram above—the distributed table prefers a local replica if available, but other load balancing strategies can be used.
Where to find more information
For more details beyond this high-level introduction to table shards and replicas, check out our deployment and scaling guide.
We also highly recommend this tutorial video for a deeper dive into ClickHouse shards and replicas: